Apple’s AI Breakthrough: Crafting 3D Objects with Realistic Lighting from a Single Image
Apple’s research team has unveiled a groundbreaking artificial intelligence model capable of reconstructing three-dimensional objects from a single two-dimensional image, while accurately preserving intricate lighting effects such as reflections and highlights across various viewing angles.
Understanding Latent Space in Machine Learning
To appreciate the significance of this development, it’s essential to grasp the concept of latent space in machine learning. Latent space refers to a multi-dimensional representation where complex data, like images or text, are encoded into numerical vectors. This encoding allows for efficient computation and manipulation of data by capturing underlying patterns and relationships.
For instance, in natural language processing, words can be represented as vectors in latent space, enabling operations like vector arithmetic to uncover semantic relationships. Similarly, images can be encoded into latent space, facilitating tasks such as image generation, transformation, and, as demonstrated by Apple’s new model, 3D reconstruction.
Introducing LiTo: Surface Light Field Tokenization
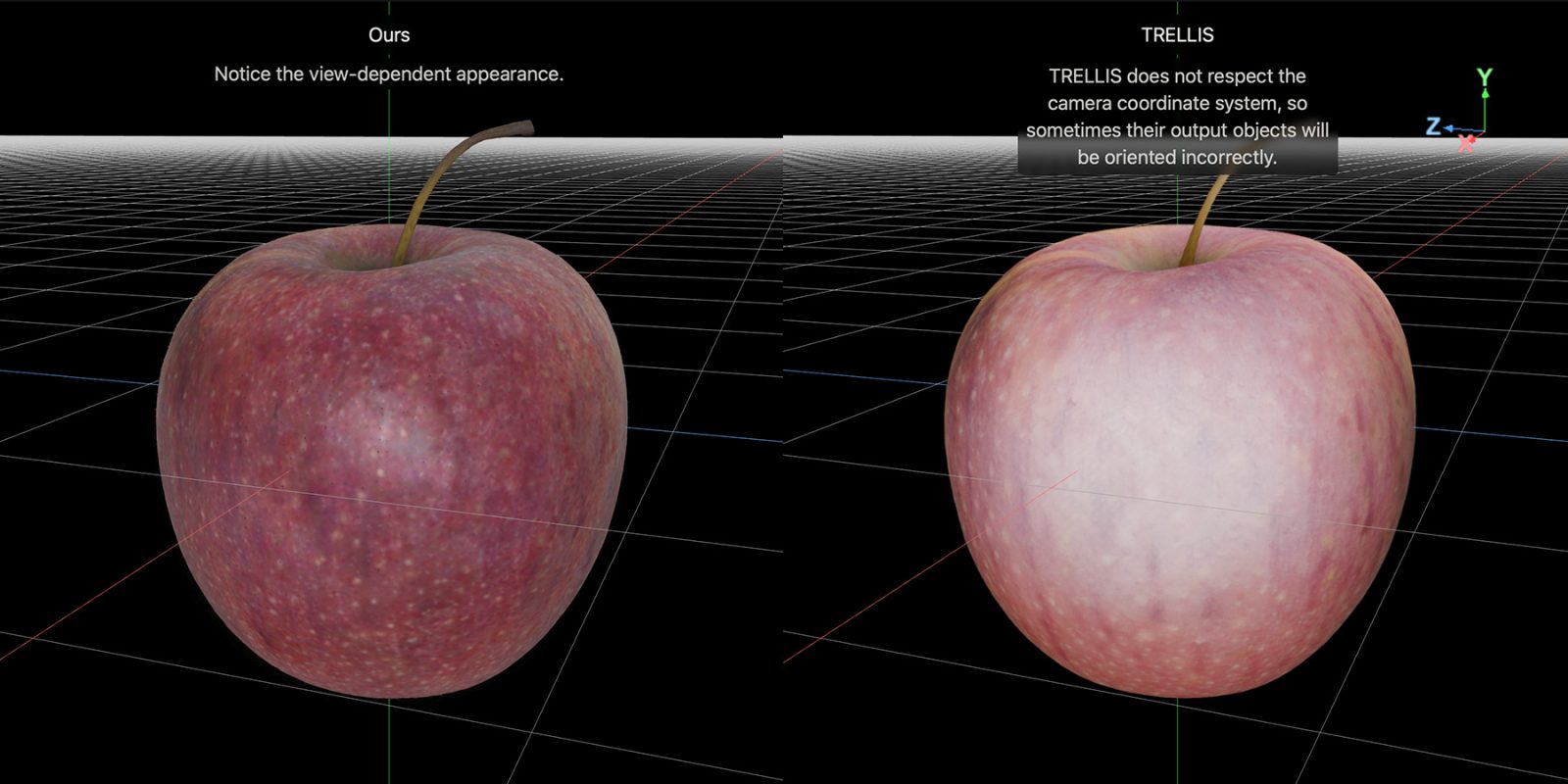
In their latest study titled LiTo: Surface Light Field Tokenization, Apple researchers introduce a novel approach that combines object geometry and view-dependent appearance into a unified 3D latent representation. This method leverages RGB-depth images to sample a surface light field, encoding these samples into a compact set of latent vectors. The result is a model capable of reproducing realistic view-dependent effects, such as specular highlights and Fresnel reflections, under complex lighting conditions.
A remarkable aspect of this model is its ability to perform 3D reconstruction from a single image. Traditional methods often require multiple images from different angles to achieve accurate 3D modeling. By contrast, Apple’s approach simplifies the process, making it more accessible and efficient.
Technical Insights into the LiTo Model
The LiTo model operates through a series of sophisticated steps:
1. Encoding the Input: An encoder compresses the information from the input image into a latent representation, capturing both geometric and appearance details.
2. Latent Space Representation: This compressed data is organized within a multi-dimensional latent space, where relationships between different aspects of the object and its appearance are maintained.
3. Decoding and Reconstruction: A decoder then reconstructs the 3D object from the latent representation, accurately rendering view-dependent lighting effects.
This process ensures that the reconstructed 3D object not only mirrors the original geometry but also exhibits realistic lighting behaviors when viewed from various angles.
Implications and Applications
The implications of this advancement are vast and varied:
– Augmented and Virtual Reality: Enhanced 3D object reconstruction can lead to more immersive AR and VR experiences, where virtual objects seamlessly integrate with real-world environments.
– E-commerce and Retail: Retailers can create detailed 3D models of products from single images, offering customers interactive views and improving online shopping experiences.
– Gaming and Entertainment: Game developers can generate realistic 3D assets more efficiently, reducing production time and costs.
– Cultural Heritage Preservation: Museums and cultural institutions can digitize artifacts using minimal imagery, aiding in preservation and virtual exhibitions.
Comparative Analysis with Previous Models
Apple’s LiTo model represents a significant leap forward compared to earlier methods:
– Matrix3D Model: Previously, Apple introduced the Matrix3D model, capable of generating 3D scenes from just three images. While impressive, it still required multiple inputs. The LiTo model’s ability to work from a single image marks a substantial improvement in efficiency and accessibility.
– Object Capture API: Apple’s Object Capture API allowed users to create 3D models using a series of photographs. However, it necessitated multiple images and specific conditions for optimal results. The LiTo model simplifies this by reducing the input requirement to a single image without compromising quality.
Challenges and Future Directions
Despite its advancements, the LiTo model faces certain challenges:
– Generalization Across Diverse Objects: Ensuring the model accurately reconstructs a wide variety of objects with different textures and materials remains a challenge.
– Computational Efficiency: While the model reduces input requirements, optimizing computational resources for real-time applications is an ongoing area of research.
Future research may focus on enhancing the model’s robustness, expanding its applicability across various domains, and integrating it into consumer-facing applications.
Conclusion
Apple’s development of the LiTo model signifies a transformative step in the field of 3D reconstruction and computer vision. By enabling the creation of detailed 3D objects with realistic lighting effects from a single image, this technology opens new avenues for innovation across multiple industries. As Apple continues to refine and expand upon this research, the potential applications are boundless, promising a future where digital and physical realities converge more seamlessly than ever before.