Apple’s Advances in Multimodal AI: Enhancing Image Understanding and Generation
Apple’s ongoing research into artificial intelligence (AI) has led to significant advancements in multimodal large language models (MLLMs), particularly in the realms of image understanding, generation, and web search capabilities. These developments are poised to revolutionize how users interact with visual content on their devices.
DeepMMSearch-R1: Revolutionizing Multimodal Web Search
One of Apple’s notable contributions is the development of DeepMMSearch-R1, a sophisticated MLLM designed to enhance web search functionalities by integrating image processing capabilities. Traditional search engines often struggle with ambiguous queries or images containing multiple elements, leading to inaccurate or incomplete results. DeepMMSearch-R1 addresses these challenges through a multifaceted approach:
– Text Search Tool: This component enables the model to retrieve up-to-date factual information from web pages, ensuring that users receive the most current data available.
– Grounding Tool: By intelligently cropping images to focus on relevant sections, the model can isolate specific elements within a picture, facilitating more precise searches.
– Image Search Tool: Utilizing both complete and cropped images, this tool gathers web content, including titles and descriptions, to provide comprehensive search results.
For instance, when presented with an image of a horse with a bird perched nearby and queried about the bird’s maximum speed, DeepMMSearch-R1 can crop the image to focus solely on the bird, identify it as an egret, and then retrieve accurate information regarding the egret’s top speed. This process ensures that users receive precise answers tailored to their specific queries.
The training of DeepMMSearch-R1 involved a two-stage process: initial supervised fine-tuning to prevent unnecessary cropping and online reinforcement learning to optimize tool usage. Evaluations have demonstrated that DeepMMSearch-R1 outperforms existing retrieval-augmented generation workflows and prompt-based search agent baselines, marking a significant advancement in multimodal information-seeking AI.
Manzano: A Unified Approach to Image Understanding and Generation
In addition to enhancing search capabilities, Apple has introduced Manzano, a unified multimodal LLM capable of both understanding and generating images without compromising on either function. Traditional models often prioritize one capability over the other, leading to trade-offs in performance. Manzano overcomes this limitation through a novel architecture:
– Unified Visual Encoder/Tokenizer: This component includes a continuous adapter for understanding tasks and a discrete adapter for generation tasks, allowing the model to seamlessly switch between interpreting and creating images.
– LLM Decoder: Accepting text tokens and continuous image embeddings, the decoder auto-regressively predicts the next discrete image or text tokens from a joint vocabulary, facilitating coherent and contextually relevant outputs.
– Image Decoder: This element renders image pixels from predicted image tokens, enabling the generation of high-quality images from textual descriptions.
By training Manzano with a combination of text-only, interleaved image-text, image-to-text, and text-to-image data, Apple’s researchers have achieved state-of-the-art performance in both understanding and generation tasks. Notably, even the compact 300 million parameter variant of Manzano performs comparably to dedicated single-task models, while larger versions (3 billion and 30 billion parameters) surpass other leading unified multimodal LLMs.
Manzano’s capabilities extend to processing complex, counterintuitive prompts, such as The bird is flying below the elephant, and performing versatile editing tasks, including instruction-guided editing, style transfer, inpainting, outpainting, and depth estimation. This versatility positions Manzano as a powerful tool for a wide range of applications, from creative content generation to advanced image analysis.
Practical Applications and Future Prospects
The integration of these advanced MLLMs into Apple’s ecosystem holds promising implications for user experience. For example, the enhanced image-related tools could be incorporated into Siri, providing users with more accurate and context-aware responses to visual queries. With the anticipated release of iOS 26.4 in the spring of 2026, Apple is expected to unveil an upgraded version of Siri powered by Google Gemini, potentially leveraging these AI advancements to offer more sophisticated and intuitive interactions.
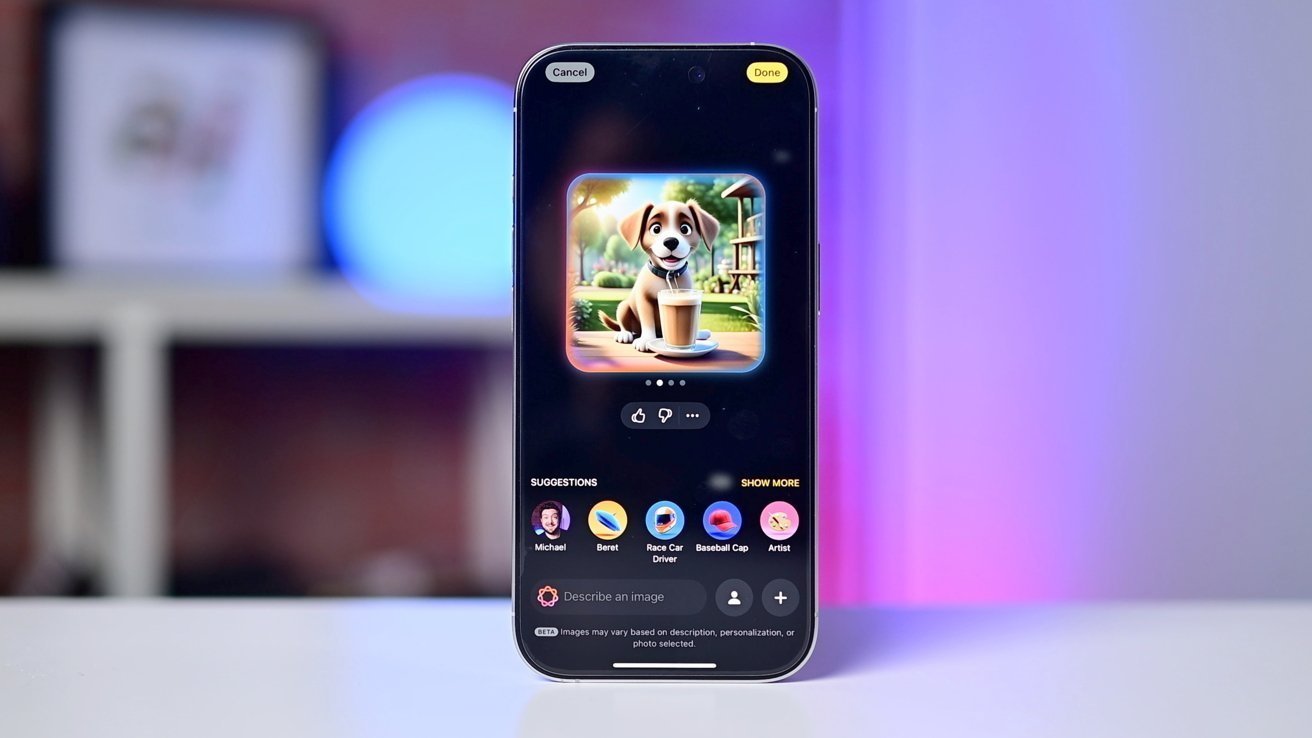
Furthermore, Apple’s commitment to on-device AI processing, as demonstrated by the introduction of Image Playground in iOS 18, underscores the company’s dedication to user privacy and data security. By enabling image generation and editing capabilities directly on devices without requiring an internet connection, Apple ensures that users can enjoy the benefits of AI without compromising their personal information.
Conclusion
Apple’s research into multimodal large language models represents a significant leap forward in the fields of image understanding and generation. Through innovations like DeepMMSearch-R1 and Manzano, Apple is not only enhancing the functionality of its devices but also setting new standards for AI integration in consumer technology. As these models continue to evolve, users can look forward to more intuitive, efficient, and secure interactions with their devices, transforming the way we engage with digital content.