Critical Vulnerabilities in GPT-4o and GPT-5 Enable Zero-Click Data Exfiltration
Recent research has uncovered seven critical vulnerabilities within OpenAI’s ChatGPT models, specifically affecting GPT-4o and the newly released GPT-5. These flaws could allow attackers to stealthily extract private user data through zero-click exploits, raising significant concerns about the security of large language models (LLMs) that millions rely on daily.
Understanding the Vulnerabilities
The identified vulnerabilities exploit indirect prompt injections, enabling malicious actors to manipulate the AI into revealing sensitive information from user memories and chat histories without any direct user interaction. This means that simply posing a benign query could inadvertently trigger data exfiltration.
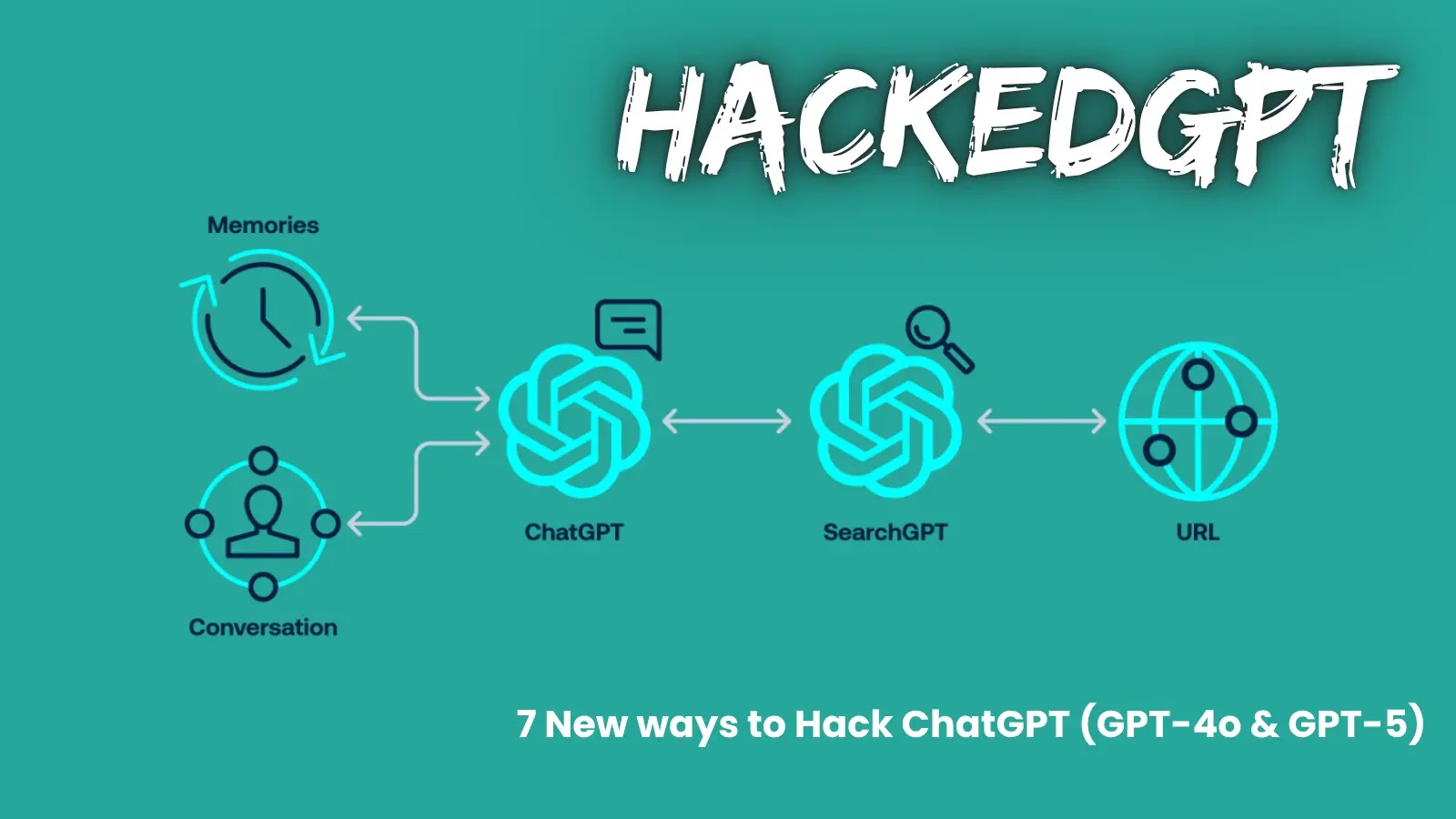
The core of these issues lies in ChatGPT’s architecture, which utilizes system prompts, memory tools, and web browsing features to provide contextual responses. The system prompt defines the model’s capabilities, including the bio tool for long-term user memories and the web tool for internet access. While these features are designed to enhance user experience, they also introduce potential security risks.
Detailed Examination of the Seven Vulnerabilities
1. Indirect Prompt Injection via Browsing Context: Attackers can embed malicious instructions in web content, such as blog comments. When ChatGPT’s browsing tool processes this content, it inadvertently executes the hidden commands, compromising user data without their knowledge.
2. Zero-Click Indirect Prompt Injection in Search Context: By creating and indexing websites with embedded malicious prompts, attackers can manipulate ChatGPT’s search functionality. When users search for specific topics, these malicious sites appear in results, leading to data exfiltration without any user interaction beyond the initial query.
3. One-Click Prompt Injection via URL Parameter: Malicious actors craft URLs with embedded prompts (e.g., chatgpt.com/?q=malicious_prompt). When users click these links, ChatGPT processes the embedded prompt, leading to unintended actions or data leaks.
4. Bypassing Safety Mechanisms with url_safe: Attackers exploit whitelisted Bing.com tracking links to bypass OpenAI’s safety filters. This method allows malicious redirects that can exfiltrate user data, circumventing built-in protections.
5. Conversation Injection: By inserting specific instructions into SearchGPT’s output, attackers can manipulate ChatGPT to execute commands from the conversational context. This technique enables chained exploits, where one vulnerability leads to another, amplifying the potential damage.
6. Hiding Malicious Content: Utilizing markdown rendering flaws, attackers can conceal injected malicious prompts from the user’s view. These hidden prompts remain in the model’s memory, ready to be exploited in future interactions.
7. Persistent Memory Injection: Attackers can manipulate ChatGPT to update its persistent memory with malicious instructions. This means that private data can continue to be leaked in future sessions, even if the initial exploit is addressed.
Proofs of Concept and OpenAI’s Response
Tenable researchers demonstrated full attack chains, illustrating how these vulnerabilities could be exploited in real-world scenarios. For instance, a user seeking information on a niche topic might encounter a malicious blog post. When ChatGPT summarizes this content, it could inadvertently execute hidden commands, leading to data exfiltration.
Upon disclosure of these vulnerabilities, OpenAI took immediate action to address the issues. Technical Research Advisories (TRAs) were issued, and fixes were implemented to mitigate the risks. However, this incident underscores the ongoing challenges in securing AI models and the importance of continuous vigilance.
Broader Implications for AI Security
The discovery of these vulnerabilities highlights the evolving landscape of AI security threats. As LLMs become more integrated into daily life, ensuring their security is paramount. This incident serves as a reminder of the potential risks associated with AI technologies and the need for robust safeguards.
Recommendations for Users and Developers
– Stay Informed: Regularly update yourself on the latest security advisories related to AI tools you use.
– Exercise Caution: Be wary of clicking on unfamiliar links or interacting with unverified content, especially when using AI models with web browsing capabilities.
– Implement Security Best Practices: Developers should adhere to secure coding practices and conduct thorough testing to identify and mitigate potential vulnerabilities.
Conclusion
The identification of these seven vulnerabilities in GPT-4o and GPT-5 serves as a critical wake-up call for the AI community. It emphasizes the need for ongoing research, proactive security measures, and user education to safeguard against emerging threats in the rapidly advancing field of artificial intelligence.


