In the rapidly evolving landscape of artificial intelligence (AI), the demand for powerful hardware to run complex models has become a standard. However, a recent experiment by software developer Andrew Rossignol challenges this notion by successfully running a modern large language model (LLM) on a 2005 PowerBook G4. This endeavor not only highlights the adaptability of AI models but also underscores the potential of older hardware in contemporary applications.
The Experiment: Breathing New Life into Old Hardware
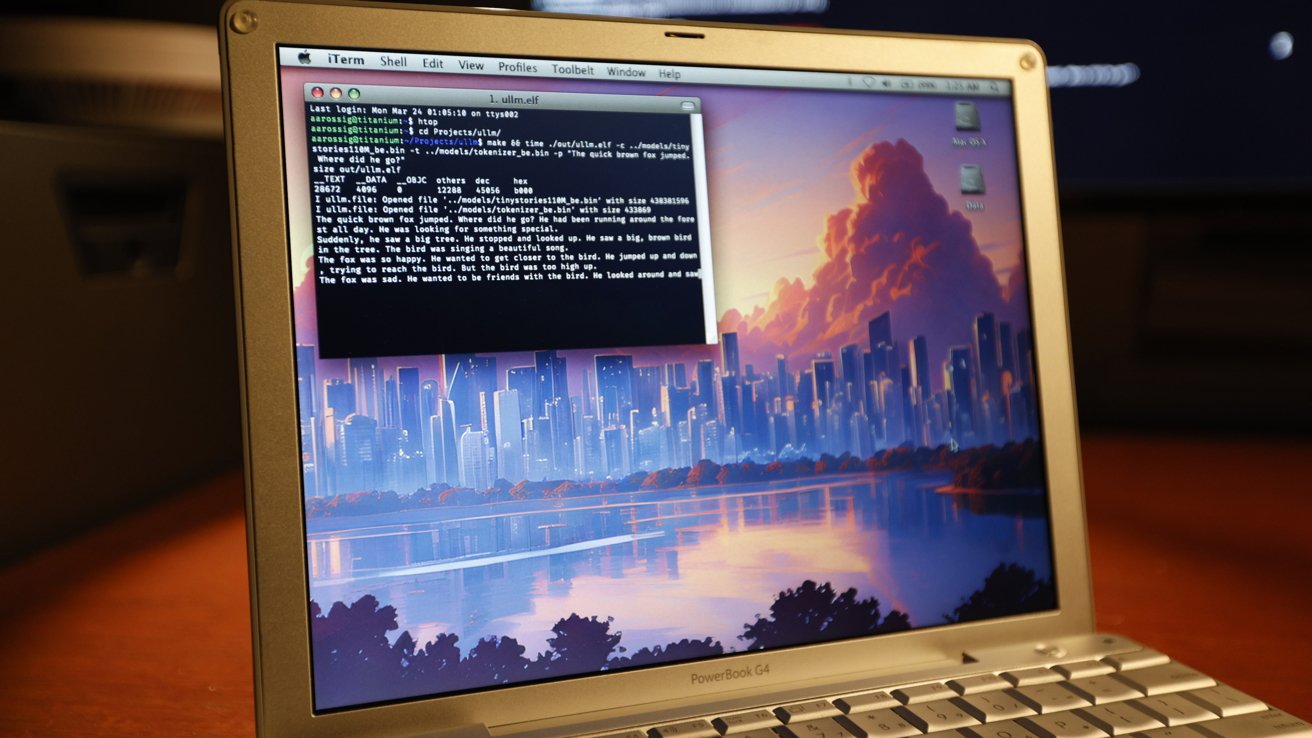
Andrew Rossignol, known for his innovative projects, embarked on a mission to run a modern LLM on a 2005 PowerBook G4. This particular model, equipped with a 1.5GHz PowerPC G4 processor and 1GB of RAM, represents the pinnacle of early 2000s laptop technology. Despite its age, Rossignol aimed to demonstrate that such hardware could still perform tasks typically reserved for modern machines.
Technical Challenges and Solutions
The primary challenge was the PowerBook G4’s 32-bit architecture and its “big-endian” processor, which contrasts with the “little-endian” systems that most modern models are designed for. To address this, Rossignol utilized the llama2.c project, an implementation of the Llama2 LLM inference in C. He made several modifications, including:
– Developing wrappers for system functions to ensure compatibility.
– Organizing the code into a library with a public API for better structure.
– Porting the project to run on PowerPC Macs, addressing the endianness issue.
These adjustments were crucial in adapting the model to the PowerBook’s architecture.
Performance Metrics: A Test of Patience
Performance testing involved running the TinyStories model, specifically the 15 million-parameter (15M) variant, before moving to the 110M version. The choice of model size was dictated by the PowerBook’s limited address space. For comparison, the same model was run on a single Intel Xeon Silver 4216 core clocked at 3.2GHz, achieving a query time of 26.5 seconds and processing 6.91 tokens per second.
On the PowerBook G4, the results were markedly slower:
– Initial inference time: Approximately 4 minutes per query, nine times slower than the Xeon core.
– After optimizations, including the use of AltiVec vector extensions: Reduced inference time by 30 seconds, making it eight times slower than the Xeon core.
Despite the sluggish performance, the PowerBook successfully generated outputs, including whimsical children’s stories, showcasing its capability to handle LLM tasks, albeit at a reduced speed.
Implications and Reflections
This experiment serves as a testament to the resilience and adaptability of older hardware. While the PowerBook G4’s performance is not on par with modern machines, its ability to run a contemporary LLM opens discussions about the potential reuse and repurposing of outdated technology. Rossignol himself noted the impressiveness of a 15-year-old computer performing such tasks, emphasizing the value of understanding and optimizing existing hardware.
Conclusion: A Nod to the Past with an Eye on the Future
Rossignol’s project is more than a technical achievement; it’s a reminder of the potential that lies in older technology. As AI continues to advance, this experiment encourages a broader perspective on hardware requirements and sustainability. It challenges the industry to consider how existing resources can be leveraged in the pursuit of innovation.


